Values that are too far from the rest of the observations
Day 2: Predictions and Finding Outliers
Our model did not do a very good job in predicting revenue. We have to consider that outliers, number of meals sold were more that our 1-4 normally sold.
For example, record 150, 152 in the spreadsheet, the actual revenue was $60.25. Our model predicts $80 for the revenue. That is a large discrepancy. Let's look at some metrics for model errors. Use the following code.
from sklearn import metrics print('RMSE:', np.sqrt(metrics.mean_squared_error(y_test, pred_y)))
You should get the following output.
RMSE: 9.856476253257808
Low RMSE values indicate that the model fits the data well and has more precise predictions. Conversely, higher values suggest more error and less precise predictions.
One way to assess how well a regression model fits a dataset is to calculate the root mean square error, which is a metric that tells us the average distance between the predicted values from the model and the actual values in the dataset.2
Our calculated RMSE is $9.85. That means our predictions differ $9.85 from actual amounts.
We really can't use this model for predicting future revenue. We need to see what caused the large discrepancy.
If we have any outliers that could throw off our precictions. That is what we are going to do in the next section
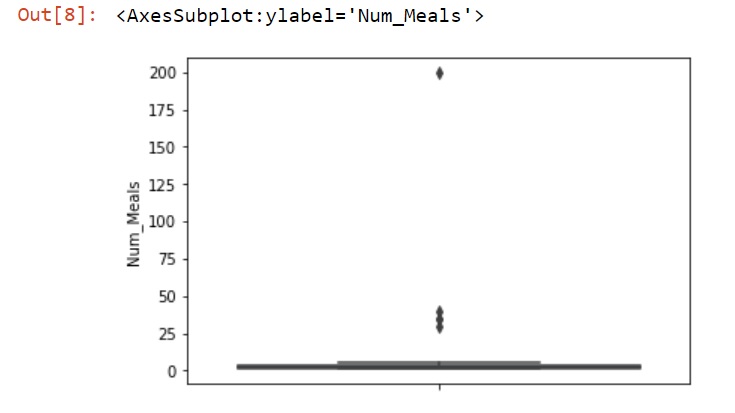
A good way to see outliers is by using a box plot.
Create a new frame, click copy text button and paste the contents into the frame.
Run the code for all frames.
Output for this frame should look like the data below.
The box plot shows us that most of the meals sold are between 1 and 5.
The graph also shows the outliers. They are the black dots. There are some between 25 and 50 and one at 200. These items can negatively affect our statistical model. We need to deal with these outliers to create a better model.
One of the most used way to remove them is to find the Inter Quartile Range (IQR). Multiply it by 1.5 and then subtract it from the first quartile value (.25) to find the lower limit. To find the upper limit, add the product of IQR and 1.5 to the 3rd quartile value, (.75).
IQR can be calculated subtracting the first quartile value from the 4th quartile.3
Day 3: Trimming the outliers
Outlier trimming means that we are going to remove outliers beyond a certain threshold value. We are going to remove outliers from the number of meals column. These large number of meals were for catering events and do not give us a clear picture of our day to day revenue.
Create a new frame, click copy text button and paste the contents into the frame.
Run the code for all frames.
Output for this frame should look like the data below.
-2.0
6.0
Any outlier(number of meals) less that -2 or over 6 need to be eliminated
Now we need find the rows containing those oulier values.
Create a new frame, click copy text button and paste the contents into the frame.
There is no output from this code.
Create a new frame, click copy text button and paste the contents into the frame.
There is no output from this code.
Now let's see how many rows were eliminated. Create a new frame and key in this code.
This shows that the original data set contained 776 rows and 4 columns. The new dataset after eliminating the outliers shows 771 rows and 4 columns. We eliminated 5 rows (776-771).
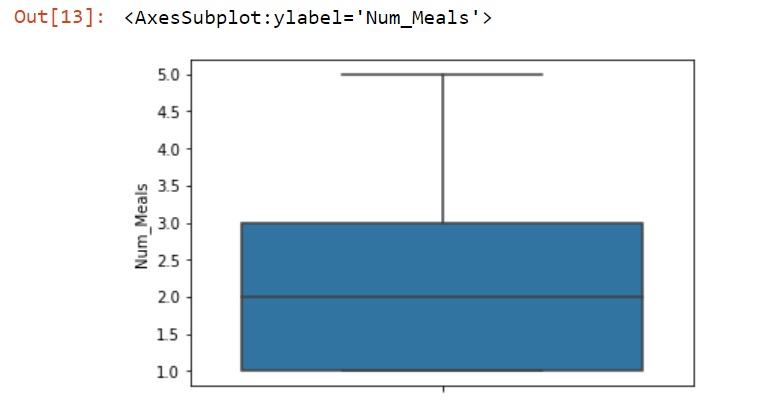
Now we are going to plot a box plot to verify that the outliers have been eliminated before we begin to train the model.
You can see from the box plot that there are no more outliers.
Create a new frame, click copy text button and paste the contents into the frame.
These lines of code sets new variables for X and y after eliminating the rows containing outliers.
There is no output from this line of code.
Create a new frame, click copy text button and paste the contents into the frame.
Save and run all frames.
You should get the following output.
Coefficient
Location -0.039951
Num_Meals 12.128038
Time -0.000256
Now we can predict that for every additional meal sold, revenue will increase by $12.12. Remember that this number was $19.67 before eliminating the outliers.
Next, we need to see individual predictions.
Create a new frame, click copy text button and paste the contents into the frame.